

Predikce větvení (anglicky branch prediction) je součástí všech pokročilých procesorů a značným způsobem ovlivňuje jejich výkon. V poslední době jsem věnoval trochu času analýze a testování jednotlivých metod predikce větvení, a napadlo mě, že bych z nasbíraných výsledků mohl vytvořit článek, který rozebere jednotlivé metody pro predikci větvení. Článek začne pomalu se statickou predikcí, následně prosvištíme metodami, které vyžadují spolupráci programátora/kompilátoru, poté se konečně dostaneme k dynamické predikci větvení.
Vzhledem k množství času potřebného k testování jednotlivých metod bude článek postupně aktualizován a doplňován o čím dál pokročilejší metody predikce. Hned z kraje můžu prozradit, že dosáhnout 90% úspěšnosti bude hračka a brzy této mety dosáhneme.
Doufám, že se článek bude líbit :)
- Metodika
- Úvod do predikce větvení, aneb proč vlastně predikovat?
- Statická predikce
- Always Taken/Not Taken
- Backward Taken Forward Not Taken
- Eager Execution
- SW metody predikce
- Hint bit
- Delay slot
- Dynamická predikce
- Single bit
- 2-bit Saturating counter
- Local prediction
- Správné adresování
1. Metodika
Veškeré testování bylo provedeno na infrastruktuře ze soutěže Championship Branch Prediction (dostupná zde https://www.jilp.org/cbp2016/), test je složen ze 440 souborů, z nichž každý obsahuje 1-100 miliónů instrukcí. Soubory jsou příklady programů z jak serverového prostředí, tak i z klasického desktopu - rozhodně bych se tedy nebál, že náš testovací vzorek nebude reprezentativní (až tedy na malou nuanci u statické predikce, na kterou Vás upozorním).
Trochu bych chtěl naťuknout způsob vyhodnocování přesnosti jednotlivých prediktorů. Asi nejintuitivnější je uvádět přesnost v procentech. Ale v praxi, kdy inženýři navrhují prediktory s 98+% přesností, procenta přestávají být relevantní metrikou přesnosti (protože 98,1% a 98,2% působí jako úroveň odchylky měření, ale ve skutečnosti je to podstatný rozdíl). Zavedla se proto nová metrika MPKI (Misspredictions Per Thousand Instructions), která vyjadřuje počet mispredikcí na 1000 instrukcí.
Jelikož infrastruktura CBP vyhazuje výsledky rovnou v MPKI (a bohužel je nejde jednoduše přepočítat na %), budu uvádět hlavně tyto údaje. Později bych chtěl přidat % údaje pro základní metody.
Všechny grafy doporučuju otevřít v novém okně - ze začátku to tak možná nebude, ale postupně se prokoušeme k méně přehledným grafům a jejich roztáhnutí na celý displej může věci pouze zpřehlednit.
Velikost dynamických prediktorů
Velikost (cenu) prediktorů budeme měřit v bitech/bytech - to může znít zvláštně, ale dynamické prediktory jsou vlastně velmi rychlá paměť, do které se ukládá různá historie. Dává tedy smysl udávat velikost prediktorů v bitech/bytech.
V procesorech se běžně nacházejí rychlé paměti Cache - ty mají velice podobnou strukturu jako naše prediktory, lze je tedy použít jako vodítko, jak velké prediktory jsou reálné. Pro představu lze tedy říct, že velikost prediktorů v moderních procesorech AMD/Intel může být řádově dost podobná jako velikost L1 Cache - bavíme se o rozmezí od pár KB až do stovky KB, nejpravděpodobněji pár desítek KB. Toto uvádím jen pro orientaci, jak jsou vlastně prediktory velké. Konkrétní velikosti prediktorů znají jen inženýři z Intelu/AMD.
V soutěži Championship Branch Prediction 2016 se soutěžilo v kategoriích 8KB, 64KB a neomezená velikost prediktorů.
2. Úvod do predikce větvení, aneb proč vlastně predikovat?
Kdykoliv programátor použije slůvko "if", vytvoří podmínku. Takováto podmínka rozdělí běh programu do dvou větví. Dnešní procesory jsou vysoce paralelizované, tj. vykonávají mnoho instrukcí najednou (cca 100, pokud máme mluvit o moderních CPU Intel/AMD), v momentě kdy má být programátorovo "if" zpracováno, nastane problém - procesor neví, co za instrukci má načíst jako další, protože proud instrukcí může pokračovat dvěma cestami. Kontrolní jednotka tedy provede pipeline stall - pipeline nebude načítat žádné nové instrukce do doby, než procesor zjistí, jestli podmínka "if" bude přijata (logická 1, nebo T jako Taken) nebo odmítnuta (logická 0, nebo N jako Not taken). Aby jsme se vyhnuli stallování pipeline, byla vynalezena predikce větvení - procesor si tipne, že větev bude přijata/odmítnuta a začne spekulativně vykonávat následující instrukce. Pokud později zjistí, že si tipnul špatně, "závadné" instrukce jsou zahozeny (pipeline flush) a procesor počítá odznovu.
Je potřeba zdůraznit, že v momentě kdy si procesor takto "vsadí" že větev bude přijata/odmítnuta, dochází ke spekulativní exekuci - procesor vykonává kód, o kterém neví, zda by ho měl vůbec vykonávat (toto dost porušuje Von Neumannovo schéma, které neuznává ani vykonávání více instrukcí najednou natož spekulativní nebo rovnou out of order exekuci).
Pojem spekulativní exekuce byl v posledním době dost skloňován ve spojení s chybou Meltdown, kdy procesor spekulativně umožní škodlivému programu přístup k datům (škodlivý program "zmanipuluje" prediktor větvení, aby ho k datům dočasně pustil, než dojde k pipeline flush), ke kterým by jinak přístup neměl.

Na tomto obrázku je zobrazeno schéma jednoduchého MIPS jádra, které používá pipelining (zpracování instrukce je rozděleno do 5 kroků), je skalární (jádro sice pracuje na 5 instrukcích zároveň, ale za každý takt dokončí pouze jednu instrukci) a zároveň je in-order (zpracovává instrukce tak, jak jdou za sebou).
- První krok v pipeline, jmenovitě "Fetch", slouží k získání instrukce z paměti - v tomto kroku známe pouze PC (Program Counter, adresa aktuálně zpracovávané instrukce - na obrázku lze úplně vlevo vidět registr s názvem PC), ještě vůbec nevíme, co za instrukci vlastně načítáme (add, branch, jump..). Aby se naše pipeline neflákala, potřebujeme na začátku každého cyklu znát adresu následující instrukce (neboli Next PC).
- Druhý krok, "Decode", dekóduje instrukci, kterou jsme získali v prvním kroku. Zde již máme přístup k instrukci v celé její kráse a dozvídáme se, o jakou instrukci se jedná - zjistíme, že se jedná o branch. Známe již její cílovou adresu
- Třetí krok, "Execute", konečně zpracuje data získaná v předchozích krocích a vyhodí nám výsledek - tedy jestli je naše větev přijata nebo ne.
- Ve čtvrtém kroku, "Memory acces", konečně vidíme mux (multiplexer), který nám vyhodí naši adresu Next PC.
- Pátý krok, "Write back", zůstává v případě instrukce branch nevyužit.
Proč Vám toto povídám? Pro pochopení důležitosti predikce větvení je nutné mít představu, jaká penalizace nás čeká v případě mispredikce.
V tomto případě je naše penalizace tři cykly - během Decode se nám nepodaří získat adresu další instrukce (první promarněný cyklus), během Execute pouze zjistíme, zda je větev přijata (druhý promarněný cyklus) a PC Next dostaneme až ve čtvrtém kroku (třetí promarněný cyklus), a až v dalším cyklu můžeme načíst novou instrukci z této adresy.
Větve představují zhruba pětinu všech instrukcí. Pokud by naše jádro mělo zpracovat 1000 instrukcí, 200 z nich by byly větve. Za každou z nich promarníme tři cykly, tj. celkem 600 cyklů. Naše jádro vykoná 1000 instrukcí za 1600 cyklů, větve způsobily 60% nárůst času potřebného k vykonání programu.
60% není zas tak moc. Ale je potřeba si uvědomit, že situace bude vypadat razantně jinak, když přesedláme z takto jednoduchého jádra na nabušené superskalární out-of-order jádro.
Pro zajímavost zde doplňuji (přibližné) penalizace za mispredikci pro některá moderní CPU jádra, údaje o procesorech ARM pochází přímo od ARMu, u procesorů x86 jsou použity hodnoty které uvádí Agner Fog ve svých optimalizačních manuálech (ty považuji za věrohodnější než údaje od Intelu/AMD, vzhledem k tomu že vychází z reálného testování. Vřele doporučuji jeho 3. optimalizační manuál, byl to jeden z mých zdrojů, když jsem s predikcí větvení začínal):
ARM Cortex A77 - 10 cyklů při hitu micro-op cache, jinak 11 cyklů (pravděpodobně)
ARM Cortex A76 - 11 cyklů
AMD Buldozer/Piledriver/Steamroller/Excavator - AMD uvádí 20 cyklů pro větvě a 15 cyklů pro nepodmíněné skoky a návraty, měření Agner Foga uvádí 19 cyklů pro větve a 22 cyklů pro návraty (hodnotu pro nepodmíněné skoky neuvádí)
AMD Zen 1 - zhruba 18 cyklů
AMD Zen 2 - doplním v budoucnu
AMD Jaguar/Bobcat (jádro Jaguar je použito v PS4 a XONE) - AMD uvádí 13 cyklů, Agner Fog 8 až 19 cyklů s tím, že konkrétní hodnota záleží na následujících instrukcích
Intel Sandy Bridge - 15 cyklů při hitu micro-op cache
Intel Haswell/Skylake - 15 až 20 cyklů
Intel Ice Lake (jádro Sunny Cove) - doplním v budoucnu
Zkusíme si podobný výpočet aplikovat na modelové moderní x86 CPU (které bude parametry hodně podobné jádrům od Intelu a AMD):
Penalizace za mispredikci - 20 cyklů (toto může být trochu zavádějící parametr, protože u takto pokročilého jádra se jedná o minimální penalizaci - můžeme čekat (a často budeme) ještě déle než už tak dlouhých 20 cyklů)
Počet instrukcí zpracovávaných najednou - 5
Máme našich 1000 instrukcí, z toho 200 větví. Čas potřebný na zpracování 1000 instrukcí je pouhých 200 cyklů (zpracováváme 5 instrukcí najednou, 1000/5), ale k tomu musíme přičíst penalizaci za mispredikci, celých 4000 cyklů (počet větví krát penalizace za mispredikci, 20 * 200). 4200 cyklů na zpracování 1000 instrukcí.
Ukázalo se, že naše nabušené jádro má bez predikce větvení 2x nižší IPC než jedno z nejzákladnějších MIPS jader.
Ale pokud použijeme predikci větvení, dostaneme o poznání zajímavější výsledky:
Přesnost 30%: 200 + (0,7 * 200 * 20) = 3000 cyklů
Přesnost 50%: 200 + (0,5 * 200 * 20) = 2200 cyklů
Přesnost 80%: 200 + (0,2 * 200 * 20) = 1000 cyklů
Přesnost 90%: 200 + (0,1 * 200 * 20) = 600 cyklů
Přesnost 99%: 200 + (0,01 * 200 * 20) = 240 cyklů
Toto už vypadá lépe. Bez predikce větvení bychom mohli zapomenout na hry v takové podobě, jako máme dnes.
Poslední věc, kterou bych v této úvodní (a věřím že nudné) kapitole chtěl zmínit, je BTB (Branch Target Buffer, někdy i Cache of target addresses). BTB je velmi podobný klasické Cache, jen se do něj ukládají cílové adresy větví. Když dojde k Fetch, procesor prohledá BTB zda v něm není záznam pro aktuálně zpracovávanou instrukci. Pokud ano, ví že aktuální instrukce je větev. Zeptá se pak prediktoru, jestli tato větev bude přijata. Ten buď vrátí 1 (Next PC bude adresa z BTB) nebo 0 (Next PC bude instrukce následující hned za větví). BTB může obsahovat i jiné informace než cílovou adresu např. historii chování větve.
Ne každý procesor musí mít BTB, u jednodušších procesorů BTB chybí a predikce začíná až v kroku Decode.
3. Statická predikce
A. Always Taken/Not Taken
Statická predikce na rozdíl od dynamické nevyužívá žádnou formu historie. Díky tomu se jedná o velmi levnou metodu, oblíbenou u nejjednodušších procesorů. Úplně nejzákladnější forma je predikovat vždy 1 nebo 0.
Pokud budeme pokaždé predikovat 0, dosáhneme MPKI 51,256 (připomínám, že nižší MPKI = lepší), neboli přibližně 60%.
Pokud budeme pokaždé predikovat 1, dosáhneme MPKI 80,383, neboli přibližně 40%.
Drobná nuance, kterou jsem zmínil v úvodu, spočívá v tom, že to jsou přesně opačné výsledky než ty, kterých bychom dosáhli v praxi (tzn. cca 60% pro vždy Not taken a 40% pro vždy Taken).
B. Backward Taken Forward Not Taken
Další forma statické predikce je o poznání důmyslnější. Je založena na informaci o tom, zda větev odkazuje na adresu větší než PC (tudíž skáče "dopředu", anglicky forward) nebo naopak menší než PC (větev skáče "dozadu", anglicky backward).
Tuto informaci můžeme lehce zneužít díky faktu, že cykly (pro procesor není mezi cyklem a běžnou větví rozdíl) které skáčou dozadu bývají N-krát přijaty (N je počet opakování cyklu) a poté jednou nepřijaty.
Pokud tedy spatříme větev, jejíž cílová adresa je nižší než PC, budeme předpokládat, že se jedná o cyklus a budeme vždy predikovat 1. V případě větve odkazující na adresu vyšší než PC budeme vždy predikovat 0.
Nevýhodou této metody predikce je, že ji můžeme provést až potom, co proběhne dekódování instrukce (musíme znát adresu cílové instrukce). Pokud chceme predikci provést hned ve fázi Fetch, musíme mít cílové adresy uložené v BTB - tuto verzi si nasimulujeme my.
A jak si tedy metoda Backward taken, forward not taken vede? S BTB o velikosti 8192 záznamů tato metoda dosáhla velmi slušného výsledku MPKI 26,191. V budoucnu pravděpodobně doplním výsledky i pro další velikosti BTB a možná i možnost neukládat celou cílovou adresu nýbrž pouze spodních N-bitů.
C. Eager Execution
Poslední metoda je spíše teoretická než praktická - Eager execution. Její princip je naprosto jednoduchý - predikce větvení úplně chybí (ale stále se jedná o způsob predikce větvení, což je trochu ironické), za to má pipeline zdvojené všechny kroky od Fetch až do "vypočítání" větve. V momentě kdy se vykonává větev, CPU vypočítá obě strany větve (jedna kopie pipeline bude počítat stranu 1, druhá kopie pipeline bude počítat stranu 0) a až CPU zjistí zda větev je/není přijata bude pokračovat ve výpočtu dané strany - nemáme zde žádnou bublinu, kdy by se naše pipeline flákala.
Je to dost brutální způsob (co se ceny provedení týče), ale dosahuje 100% přesnosti. Tento koncept brzy narazí na svůj velký problém - máme v pipeline větev, budeme zpracovávat obě strany této větve. Ale co když se v obou stranách objeví další větev, která nám rozdělí každou stranu větve na další dvě menší strany? Budeme mít 4 kopie pipeline? A co když v těch menších stranách budou další větve? Budeme mít 8 kopií pipeline?
Kvůli své extrémní cenně pro implementaci se tento způsob v praxi nepoužívá vůbec. Mnohem výhodnější než mít 4 nesmyslné kopie pipelineje vyrobit jádro, které může zpracovávat 2 instrukce za takt a přidat k tomu nějakou průměrnou metodu predikce - takové řešení bude mít mnohem vyšší výkon.
4. SW metody predikce
A. Hint bit
Často používaná metoda je tzv. Hint bit. V samotné instrukci je zakomponován bit, který má procesoru poradit (od toho název Hint bit), zda bude větev přijata či ne. Procesor se pak může zcela spolehnout na Hint bit a založit celou predikci na něm, nebo může predikci založit na kombinaci Hint bitu a nějaké formy historie (tuto metodu používal Intel u P4).
Problém by měl být vidět hned na první pohled - někdo musí nastavit Hint bit pro každou větev. Programovací jazyky umožňují, aby programátor napověděl kompilátoru (likely, unlikely), zda bude větev častěji přijata nebo odmítnuta - ale tato metoda vyžaduje spolupráci programátora, kterému se v mnoha případech nechce u každé podmínky řešit, zda bude častěji přijata nebo odmítnuta. Tuto práci může převzít i kompilátor, který sám umí nastavit Hint bity (například u podmínky p==q nastaví nulu, protože je malá šance, že zrovna tyto neznámé se budou sobě rovnat. Ale u podmínky p > 0 nastaví jedničku, protože je relativně vysoká pravděpodobnost, že p bude kladné. Navíc takováto podmínka se může vyskytovat u cyklů). Ale kompilátor není všemocný a takto nastavené Hint bity nebudou úplně ideální.
Kompilátory dokonce umožňují, aby mu programátor dal sadu vstupních hodnot, on tyto hodnoty projel programem a na základě pozorovaného chování nastavil Hint bity jednotlivých větví. Pokud je sada vstupních hodnot dobře zvolena, Hint bity budou nastaveny velmi dobře, ale v opačném případě, kdy je soubor vstupních hodnot zvolen tragicky, budou i Hint bity zvoleny tragicky.
Výhody jsou jasné - vyšší přesnost než staticky predikovat 1 nebo 0, levné na implementaci.
Nevýhod je poněkud více - je nutné, aby Hint bit podporovala přímo ISA (ISA definuje samotnou instrukční sadu. Například jádra AMD Zen a Intel Skylake jsou v mnoha ohledech rozdílná, ale obě spadají pod ISA x86, což znamená, že na obou z nich poběží kód napsaný pro x86). Pokud tedy rozhodnutí o podpoře Hint bitu nepadlo rovnou u návrhu ISA, už není možné toto rozhodnutí později jen tak změnit.
U x86 je Hint bit řešen tak, že se před instrukci branch strčí jedna 8 bitová instrukce (tudíž by to spíš měla být Hint instruction), která hraje roli Hint bitu. Z toho co se mi podařilo zjistit, tak Intel tuto metodu naposledy využíval u Pentií 4, AMD ji nepoužívalo nikdy. U moderních x86 jader jsou tyto Hint instrukce naprosto zbytečné, pouze plýtvají pamětí a komplikují instrukční sadu.
Druhá nevýhoda spočívá v samotné nutnosti nastavovat Hint bity - přesnost predikce tudíž plně závisí na snaze programátora, což nemusí být vždy ideální řešení.
A ani když budou Hint bity správně nastaveny, nemusí být přesnost predikce nijak závratná. Pokud budeme mít větev, jejíž historie bude vypadat takto "TNTNTNTNTN" (Taken, Not Taken, Taken....), nedosáhneme nikdy vyšší přesnosti než 50%.
Existuje možnost rekompilovat program za běhu - procesor bude ukládat chování větví a program se pak sám na základě uložených hodnot za běhu rekompiluje a nastaví znovu Hint bity. Ale osobně si toto řešení v praxi nedokážu moc představit, navíc by se tím neuvěřitelně zkomplikovalo schéma, jehož hlavní výhodou je jeho jednoduchost.
Většina těchto nevýhod metody Hint bit se týká použití ve velkých jádrech, kde zkrátka této metodě už dochází dech. Ale pro použití v nějakých menších jádrech, kde si ideálně koncový zákazník sám vyvine kód a zoptimalizuje Hint bity, je toto řešení velmi výhodné. Pokud se Hint bity nastaví správně, toto schéma dosahuje vyšší přesnosti než Backward taken forward not taken.
B. Delay slot
Druhou SW metodou (ačkoliv zde už bude potřeba větší podpora v HW) predikce je tzv. Delay slot. Delay slot zajišťuje, že první instrukce následující za instrukcí branch bude vždy (i když bude větev přijata) vykonána. Tato metoda neřeší samotnou predikci větvení, ale ovlivňuje penalizaci za mispredikci - snižuje ji o jeden cyklus.
Díky tomuto schématu naše výše zmíněné MIPS jádro může snížit penalizaci z 3 na 2 instrukce, čili snížení o celých 33%.
Kdyby podobnou vychytávku používalo i naše x86 jádro, snížila by se penalizace ze 100 instrukcí na 99, čili snížení o pouhé procento.
Samozřejmě je možné tuto metodu rozšířit a vykonat vždy první 2 instrukce následující po instrukci branch, zda toto rozhodnutí je rozumné rozebereme níže.
První nevýhodou je nutná podpora přímo v instrukční sadě. Tato metoda ovlivňuje v jakém pořadí budou vykonávány instrukce, a to je zásah dost hluboko do ISA. Znovu tedy platí, že nelze jen tak z ničeho nic přidat nebo odebrat podporu pro Delay slot.
Druhá nevýhoda je přidaná práce pro kompilátor - kompilátor musí najít instrukci, která je společná pro obě strany větve a její vykonání neovlivní chod programu (pokud naše if provádí a+b, nemůžeme do delay slotu použít instrukci, která mění hodnotu neznámé a nebo b). To samo o sobě není problém, problém je až to, když kompilátor nenalezne vhodnou instrukci - v tomto případě instrukce následující po branch bude NOP (No Operation, instrukce která doslova dělá nic), což je stejné jako promarnit jeden cyklus -> přijdeme o náš bonus v podobě snížené penalizace za mispredikci.
U delay slotu pro jednu instrukci toto není zas tak velký problém a kompilátor většinou nějakou tu instrukci najde, ale v momentě, kdy by jsme vždy vykonávali dvě, tři nebo dokonce čtyři instrukce následující po branch, kompilátor by měl často problém najít tolik vhodných instrukcí - proto se v praxi používá pouze delay slot pro jednu instrukci.
Tuto metodu využívá architektura MIPS (vykonána je vždy jedna instrukce po větvi), x86 naštěstí tuto metodu nepoužívá (vliv na výkon by byl zanedbatelný a zbytečně by se zkomplikovala pipeline).
5. Dynamická predikce
A. Single bit
Tato metoda ukládá jediný bit, který indikuje jakým směrem šla poslední větev.
Oproti statické predikci má tato metoda jasnou výhodu - "TTTTTNNNNN" bude mít 90% přesnost (první N bude špatně predikováno), oproti pouhým 50% kdyby jsme staticky predikovali 0 nebo 1.
Ale například "TNTNTNTNTNTN" bude mít 0% přesnost, místo 50%.
V něčem je tato metoda horší, v jiném lepší - z toho vyplývá i výsledek, který se svým MPKI 51,109 je na stejné úrovni jako Always Not taken.
B. 2-bit Saturating Counter
2-bit Saturating Counter je takový základní kámen, na kterém staví skoro všechny pokročilé metody predikce. 2-bit Counter by se do češtiny nejspíš přeložil jako 2 bitové počítadlo. Ony 2 bity znamenají, že máme 22 (základ 2 protože se pohybujeme v binární soustavě, exponent 2 protože máme 2 bity), tedy celkem 4 stavy. Ono Saturating znamená, že při přesažení čtvrtého stavu nezačneme počítat znovu od nuly, ale zůstane na čtvrtém stavu - běžný counter počítá 00, 01, 10, 11 - teď jsme využili všechny dostupné stavy a dojde k "overflow" (přesah) a counter pokračuje (1)00, (1)01...kdežto Saturating counter nikdy nepřesáhne stav 11. Vše pochopíte lépe z následujícího obrázku:
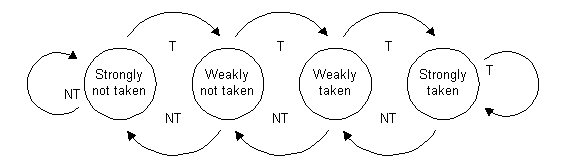
Máme celkem čtyři stavy, které se jmenují "Strongly not taken" (stav 00), "Weakly not taken" (stav 01), "Weakly taken" (stav 10) a "Strongly taken" (stav 11).
Pokud se nacházíme v levých dvou stavech (xxxx not taken), budeme predikovat 0. Pokud se nacházíme v pravých dvou stavech (xxxx taken), budeme predikovat 1.
Counter je aktualizován pomocí výsledku větve - pokud byla větev přijata, stav je posunut směrem doprava (např. z Weakly taken na Strongly taken), pokud větev nebyla přijata, stav je posunut směrem doleva.
Tento model predikce je oproti metodě Single bit více "stálejší" - single bit své rozhodnutí mění doslova ihned, kdežto 2-bit Saturating Counter je pomalejší a používá větší množství historie.
Toto umožňuje, aby "TNTNTNTNTN" mělo přesnost 50% (counter bude cestovat mezi Strongly not taken/Weakly not taken nebo Strongly taken/Weakly taken), bohužel se může stát, že se counter "zasekne" a bude cestovat mezi stavy Weakly not taken/Weakly taken - naše přesnost klesne znovu na 0%.
Za to u "TTTTTNNNNN" si pohoršíme na 80% z 90%, protože první i druhé N bude predikováno špatně (po pátém T se bude prediktor nacházet ve stavu Strongly taken, u prvního N přijde mispredikce a stav se změní na Weakly taken, znovu přijde mispredikce a stav se změní na Weakly not taken, zbylé tři větve budou predikovány správně).
A jak se posune naše přesnost? MPKI klesne na 40,012. To je stále daleko od toho, kde by jsme chtěli být, ale pomalu se posouváme dále.
Někoho možná napadne, zda lze podobně použít 3, 4, 5 bitové saturating country - nic nám nebrání zkusit to. V následujícím grafu jsou výsledky pro 2 bity, 3 bity (8 stavů, testoval jsem i omezení na 6 stavů), 4 bity (celkem 16 stavů, testoval jsem i omezení na 10, 12, 14 stavů), 5 bitů (32 stavů) a 6 bitů (64 stavů).
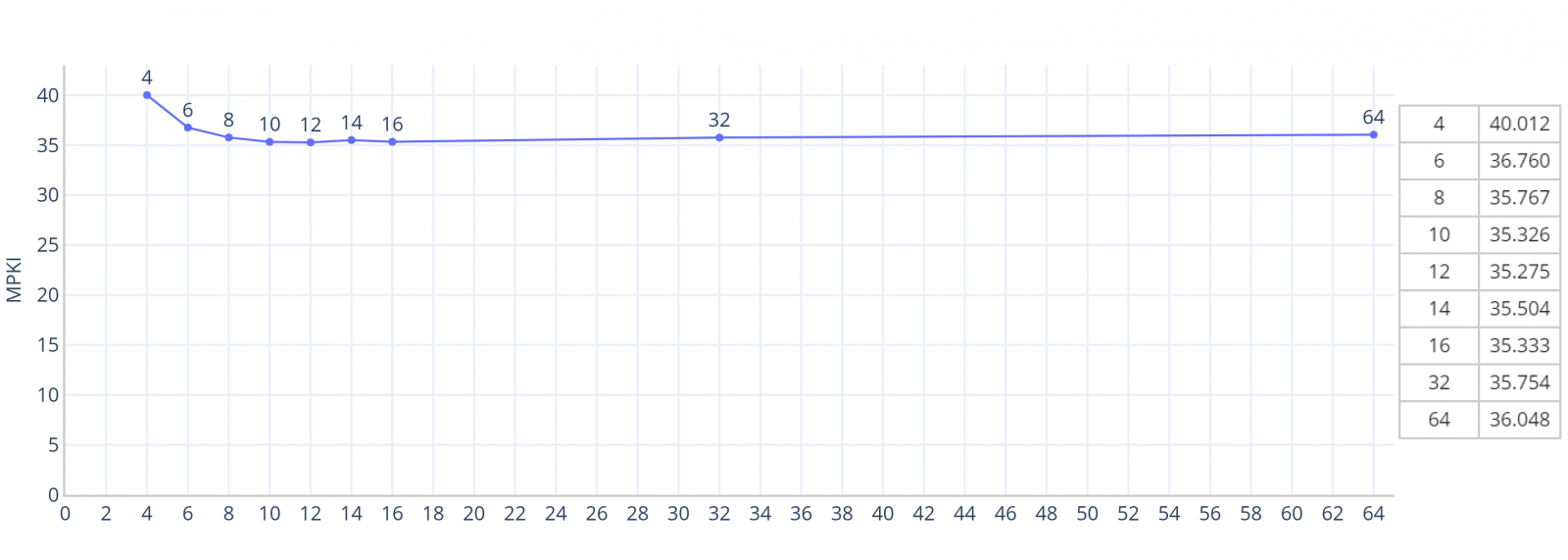
Použitím 3 bit saturating counteru jsme se vyhoupli na MPKI 35,767. Varianta se čtyřmi bity je jen o málo lepší a nejlepšího výsledku dosáhla při omezení na 12 stavů - MPKI 35,275. Při použití pěti a šesti bitů začne přesnost pomalu klesat - zvýšení počtu stavů snižuje rychlost s jakou se prediktor adaptuje na změny v chování větví - dostat se z nejzazšího stavu Not taken na první stav Taken trvá celých 32 větví.
Další možnost, jak upravit Saturating countery, je pozměnit jednotlivé stavy - můžeme mít 3 bit Saturating Counter, který bude mít 3 stavy Not taken a 5 stavů Taken (místo 4 stavů Not taken a 4 stavů Taken). Toto obvykle nepřináší nějaký smysluplný posun v přesnosti, takže to rovnou přeskočíme.
Užití 3 bitů skutečně smysl má, ale u 4 bitů je posun diskutabilní a jakákoliv vyšší hodnota už nepřináší žádné výhody - ačkoliv jsme se dočkali lepších výsledků, je jasné, že tudy naše cesta k 90% přesnosti nevede. V následujících kapitolách se zaměříme na to, jak pomocí Saturating counterů postavit ještě silnější (samozřejmě dynamické) prediktory.
6. Local prediction
Pokud se bavíme o dynamické predikci, rozeznáváme dva hlavní typy prediktorů - globální a lokální. Globální predikce hází všechny větve do "jednoho pytle", nerozeznává mezi jednotlivými větvemi. Díky tomu je globální predikce ideální, pokud potřebujeme zachytit větve, které mezi sebou korelují (závisí na sobě). Úplný opak je lokální predikce, která se zaměřuje na chování jednotlivých větví - narozdíl od globální predikce, lokální predikce nedokáže vůbec (nebo velmi špatně) zachytit korelaci mezi více větvemi.
Nelze říct, že by jeden přístup byl lepší než ten druhý - globální i lokální predikce mají své výhody a nevýhody. Naším úkolem bude najít tyto výhody/nevýhody a využít je v náš prospěch :)
Obě metody zmíněné v minulé kapitole (Single bit a 2 bit Saturating counter) fungovaly na principu globální predikce - všechny větve používaly/mapovaly se na jeden a ten samý záznam historie (bit/bity). Hlavní (ne)výhoda globální predikce byla už výše zmíněna - dokáže zachytit korelace mezi jednotlivými větvemi. Jak tato vlastnost může být pro nás nevýhodná? Když se mnoho větví mapuje na stejný záznam historie, dochází k interferenci/rušení mezi jednotlivými větvemi - větve se bijí jedna přes druhou. O vlastnostech interference (jak negativních, tak i pozitivních), jak a do jaké míry ji eliminovat se budeme bavit více do hloubky u Two level adaptive predictoru, podle mě se jedná o velmi zajímavé téma.
Nejlepší bude ukázat si rozdíl mezi globální/lokální predikcí přímo na příkladu. U 2 bit saturating counteru jsme se bavili, jak se vypořádá s patternem "TNTNTN" a došli jsme k závěru, že přinejlepším dosáhneme přesnosti 50%, ale také můžeme skončit na 0%. Toto není zrovna uspokojivá přesnost. S dovolením si tento příklad trochu upravím pro dvě větve:
01010101
Zde vidíme, jak by historie dvou prolínajících se větví vypadala z pohledu globální predikce. Jsem si jistý, že už tušíte, jak bude historie vypadat, když se na ni podíváme z pohledu lokální predikce:
0000
1111
Nyní máme dva separátní záznamy - jeden obsahuje historii první větve (žlutá), druhý obsahuje historii druhé větve (zelená).
Abych náš příklad přenesl do programátorské praxe - představte si nekonečný cyklus s podmínkou na konci (takový cyklus se tváří jako běžná větev, která má historii "1111..."), který má uvnitř podmínku "pokud dělíš 0 -> vypiš Nelze dělit nulou" - jelikož tato podmínka funguje jako preventivní opatření proti dělení nulou (matematika toto neuznává), lze předpokládat, že za běžného chodu programu tato chyba nenastane a my dostaneme historii "0000...".
Když spustíme program, bude se nám střídat cyklus a podmínka proti dělení nulou. Dostaneme náš pattern "01010101".
Nyní ale vyvstala jiná otázka - jak se vypořádat s dvěmi záznamy historie? Odpověď je tak jednoduchá, jak jen může být - prostě použijeme dva 2 bit saturating country.
Snad nebude problém určit, kam se posune přesnost, pokud "zelená" i "žlutá" větev dostane svůj vlastní 2 bit saturating counter. Jelikož se nám podařilo z poměrně problematického patternu "10101010" udělat dva primitivní a bezproblémové patterny "1111" a "0000", potom co se prediktor zahřeje (dostane se z výchozí stavu do ustálených hodnot) dosáhneme přesnosti 100%.
Teď už zbývá jediný problém - jak vlastně rozeznat jednotlivé větve. Větví může být v programu tisíce a my musíme najít způsob, jak je rozdělit mezi jednotlivé 2 bit saturating countery.
Nejjednodušší způsob je použít pro rozlišení jednotlivých větví jejich adresu (aktuální PC) - zde využíváme toho, že programy málo kdy přepisují vlastní kód. Instrukce tedy "necestují" a jejich adresa jim zůstane stejná po celou dobu běhu programu.
Už víme, jak rozeznat jednotlivé větve. Menší zádrhel představuje fakt, že PC bývá 32/64 bitový registr (záleží zda je instrukční sada a z ní vycházející procesor 32 nebo 64 bitový), to dělá ~4,3 miliardy (4,3*109) respektive ~18,5 triliónů (18,5*1018) možných adres. Pokud bychom chtěli pro každou adresu mít vlastní 2 bit saturating counter, musel by prediktor být velký ~8,6Gb = 1,1GB respektive ~37Eb (Exabitů) = 4,6EB (Exabytů).
Teď bych chtěl připomenout, že na začátku v kapitole Metodika jsme si uvedli, že i velké prediktory mají několik desítek KB. Je tedy vysoce nereálné jen uvažovat o tom, že by každá adresa dostala svůj vlastní 2 bit saturating counter.
Jak to tedy vyřešit? Programy stejně nevyužívají trilióny větví, je tedy naprosto zbytečné mít trilióny counterů. Pro adresování pole counterů použijeme pouze spodních N bitů adresy PC. Například pokud "N = 4" a "PC = ...101101101001" použijeme poslední 4 bity "1001". Stále se pohybujeme v binárce, takže 4 bitové číslo má přesně 24 kombinací = 16. Pokud tedy pro adresování pole counterů použijeme 4 spodní bity adresy PC, bude potřeba 16 counterů = 32 bitů (každý counter nás stojí 2 bity). Vše lépe ilustruje následující obrázek:
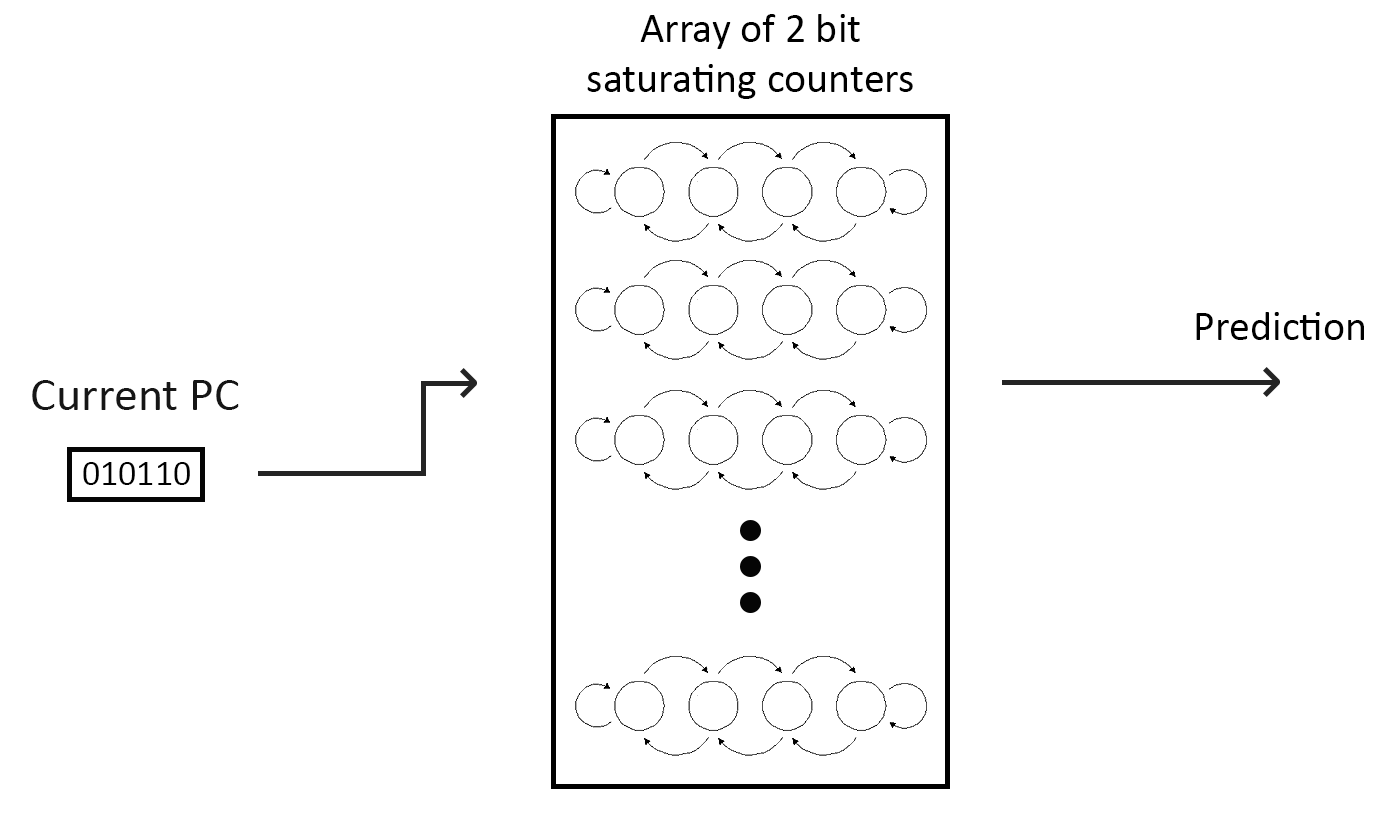
Spodních N bitů aktuálního PC použijeme pro výběr 2 bit saturating counteru z pole (kde je celkem 2N záznamů/counterů) a vybraný counter nám dá naši predikci.
Vzhledem k tomu, že nemáme trilióny counterů, na jeden counter se bude vždy mapovat více větví. Takže pokud se naše N rovná 4 a první větev má adresu "10010" a druhá má adresu "00010", obě větve se namapují do counteru s adresou "0010" a dojde tedy k interferenci/rušení. Pokud tomu chceme zabránit, musíme zvýšit N na 5 a tím zvýšit i cenu prediktoru.
Ani v lokálních prediktorech se tedy interference úplně nezbavíme, ale bude jí mnohem méně než u globálních prediktorů.
V následujícím grafu je na ose Y dosažená přesnost pro Single bit, 2-bit Saturating Counter a 3-bit Saturating Counter v MPKI (nižší = lepší), na ose X je naše N (počet bitů použitých pro adresování).
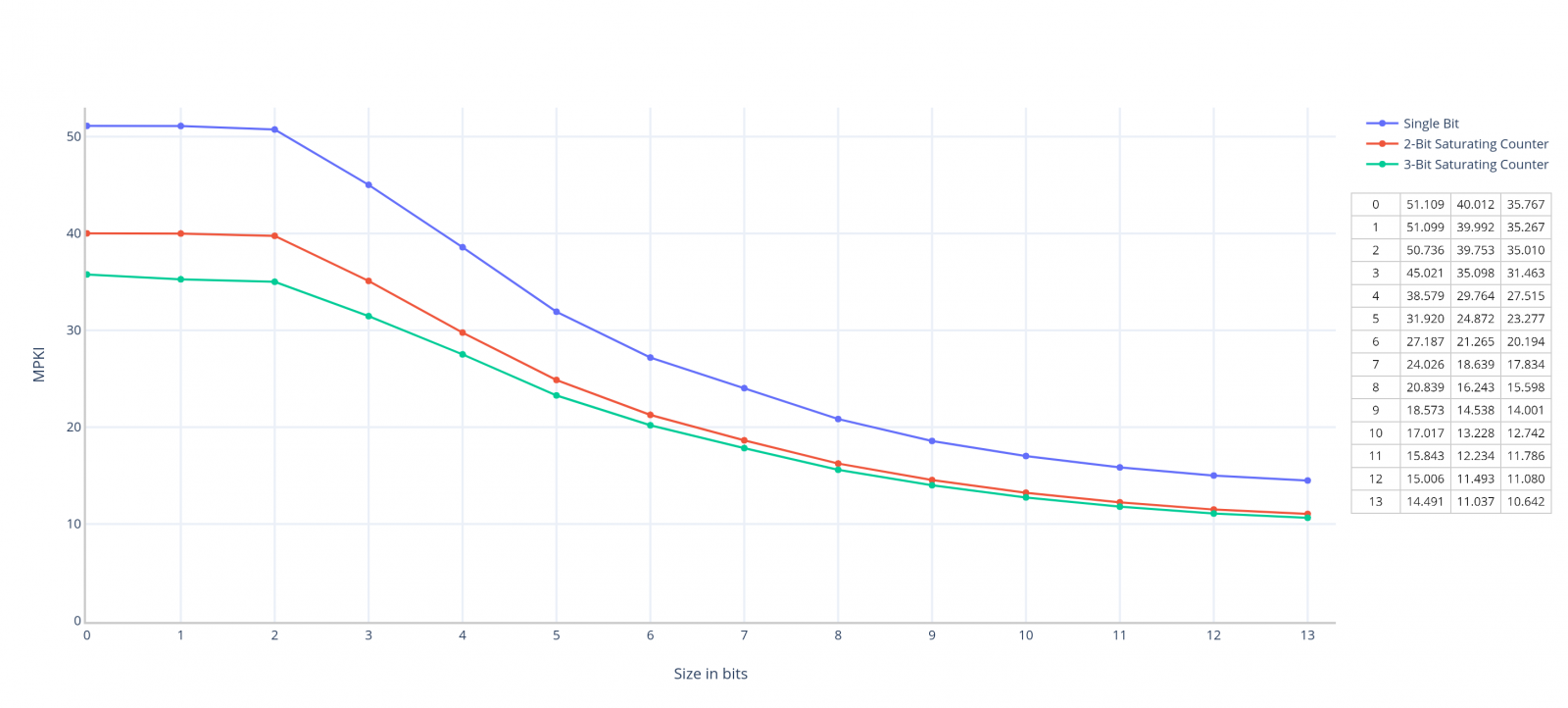
Jde vidět, že Single bit výrazně zaostává za 2/3 Bit Saturating Country. 2-Bit Saturating Counter pomalu dohání 3 bitovou variantu, ale ještě ho úplně nedohnal. MPKI se posunulo až na 10,642, což je velmi slušný výsledek. Nicméně ke konci grafu již můžeme vidět "stagnaci", počet counterů se nedá zvyšovat do nekonečna - respektive dá, ale z pohledu výkonu to nedává smysl.
Ale nesmíme zapomínat, že v grafu je porovnání podle počtu adresových bitů N, poměr cena/výkon můžeme vidět v následujícím grafu, kde je na ose X velikost v bitech:
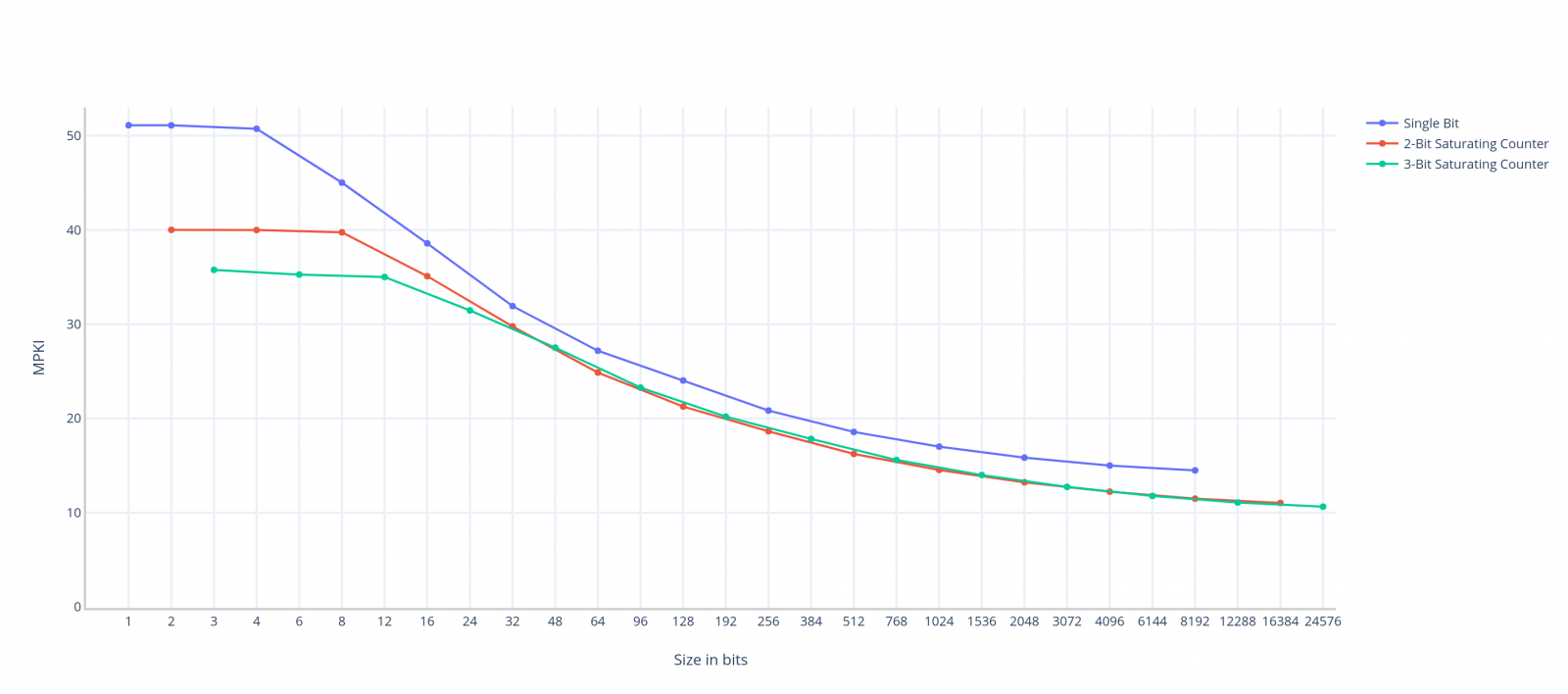
Single bit má vždy horší poměr cena/výkon než naše Saturating Country. 3 bitová varianta začíná s malým předstihem, ale 2 bitová varianta ho brzo dorovnává.
Variantě s 2-Bit Saturating Country se někdy také přezdívá Bimodal predictor, toto pojmenování se v článku nejspíš ještě párkrát objeví. Uvádí se, že opravdu velké Bimodal predictory končí s přesností na nějakých 93%, což je velmi slušný výsledek, ale taky za vysokou cenu.
Všimněte si, že přesnost prediktoru zůstává skoro stejná při použití 1, 2 a 4 záznámů (začátek křivky je rovný). Příště zkusíme přijít na to, proč tomu tak je a jak se tohoto chování zbavit.
Správné adresování
V minulé kapitole jsme si ukázali, jak funguje lokální predikce. Dosáhli jsme velmi pěkných výsledků, až na menší zádrhel - náš prediktor neškáloval při použití 2 a 4 záznamů (měl skoro stejnou přesnost, jako při použití 1 záznamu) a výraznější změny jsme dosáhli až při použití 8 záznamů (na adresování byly použity tři spodní bity PC).
Toto je zapříčiněno špatným adresováním - naše 2 respektive 4 záznamy jsou naadresovány tak špatně, že podávají stejný výkon, jako prediktor s jediným záznamem.
Pro připomenutí, my náš prediktor adresujeme tak, že vždy použijeme N spodních bitů z PC. Proč spodních? Spodní bity pro nás mají/měly by mít vyšší informační hodnotu. Na první pohled Vám nemusí být jasné, proč tomu tak je, ale podívejme se na 5 bitové číslo, ke kterému budeme postupně přičítat číslo 1 (poznámka - číslo 1 je 1 v binární i v desítkové soustavě):
00000 + 1 = 00001 + 1 = 00010 + 1 = 00011 + 1 = 00100 + 1 = 00101
Ti z Vás, kteří neumí sčítat binární čísla, nemusí vůbec zoufat. Nám tady jde pouze o to, všimnout si, jak se toto číslo mění. Když se podíváte na nejnižší bit (ten úplně vpravo, 00000), na začátku má hodnotu 0, hned po té hodnotu 1, následně znovu 0 a pak 1 - mění se tedy pokaždé. O řád vyšší bit má hodnotu 0 pak 0 pak 1 pak 1 - mění se dvakrát tak pomaleji/méně často než nejnižší bit. O řád vyšší bit (ten prostřední) má hodnotu 0 pak 0 pak 0 pak 0 pak 1 pak 1 pak 1 pak 1 - mění se tedy znovu dvakrát pomaleji/méně často, celkem tedy čtyřikrát pomaleji než nejnižší bit.
Nižší bity adresy PC se mění častěji = nesou pro nás více informací. Aby se změnil 23 bit adresy PC, museli bychom vykonat 4 milióny instrukcí (nepočítaje všechny ty větve a skoky které skáčou zpátky v instrukčním kódu).
Z tohoto důvodu je pro nás (teoreticky) lepší používat nízké bity adresy PC. Ale my v praxi vidíme, že naše škálování má daleko od ideálního.
Co s tím tedy budeme dělat? Můžeme zkusit pozměnit trochu adresování a uvidíme, zda to náš problém vyřeší - nevyužijeme N spodních bitů, ale několik spodních bitů vždy vynecháme a až poté vezmeme našich N bitů
Jestliže "N = 4" (na adresování použijeme 4 bity) a "PC = ...101101101001" při vynechání dvou spodních bitů budeme náš prediktor adresovat číslem "1010" (místo "1001", kterými jsme adresovali v minulém případě).
V následujícím grafu jsou vidět výsledky našeho prediktoru, na ose X je počet adresních bitů, na ose Y výsledná přesnost (opět nižší = lepší). Tentokrát zde máme rovnou 6 křivek - náš Bimodal prediktor s "Defaultním" adresováním tvořený 2-Bit saturating countery a jeho 5 variant kdy vynecháváme 1 až 5 spodních bitů (Shift 1 až Shift 5).
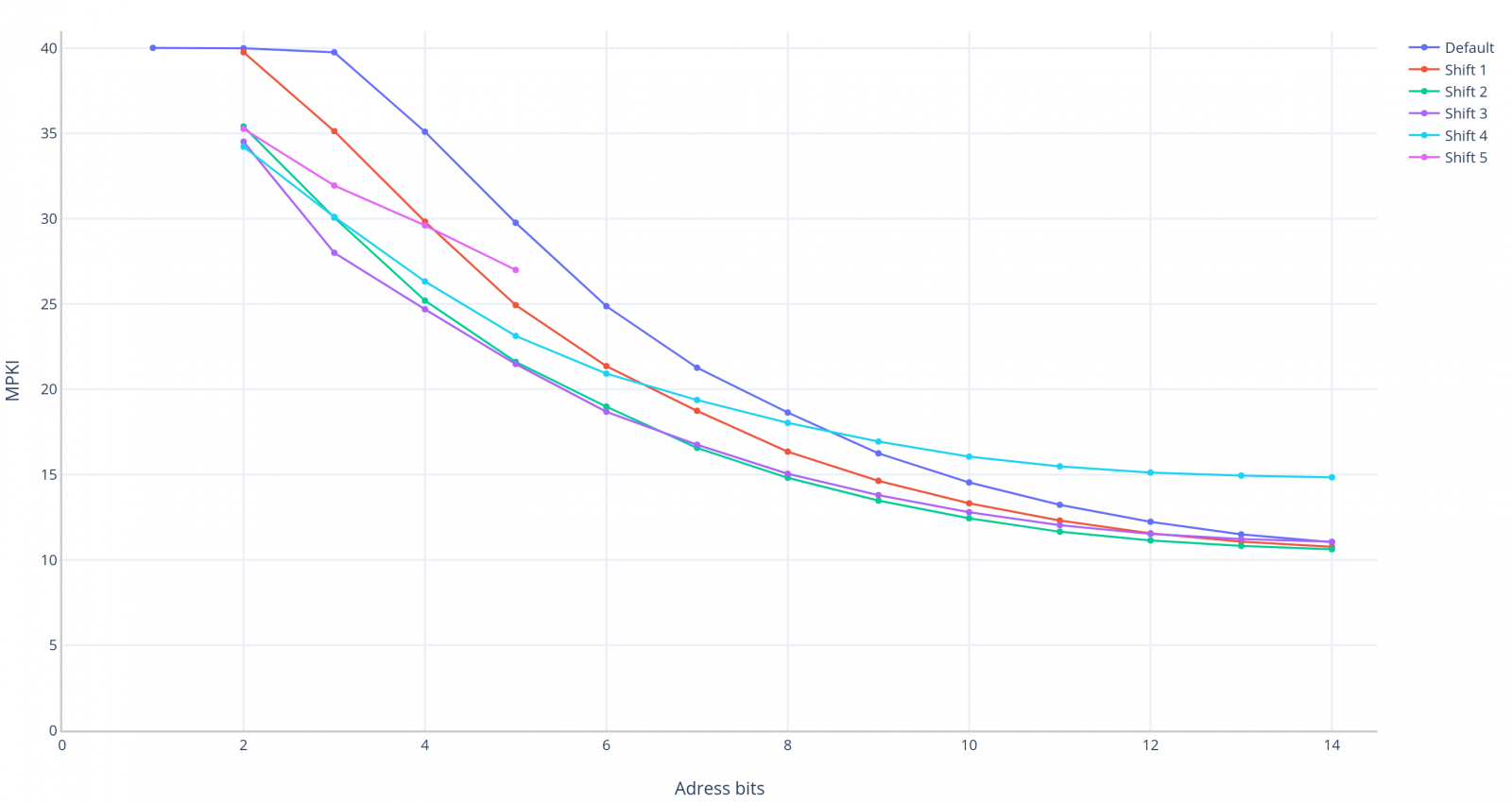
Doporučuji si graf rozkliknout v novém okně, jelikož je dost nepřehledný
Nahoře můžeme vidět náš prediktor s Defaultním adresováním reprezontovaný tmavě modrou čárou. Pod ním je rudě červený Shift 1 - pokud se pozorně podíváte, můžete jasně vidět, že červená křivka defacto kopíruje tu tmavě modrou, s tím, že je posunutá o jednu jednotku doleva (vyjma vysokých N, kdy Bimodal prediktor už špatně škáluje, respektive neškáluje vůbec). Co toto znamená? Prediktor s Defaultním adresováním a 128 záznamy má zhruba stejnou přesnost jako prediktor s adresováním Shift 1 s 64 záznamy. Zkrátka na stejnou přesnost nám stačí polovina záznamů. Všimněte si, že nám pomalu začíná mizet naše stagnování na začátku grafu.
Pokračujeme se zeleným Shift 2. Opakuje se chování, které jsme pozorovali u Shift 1 - zelená křivka je shodná s tmavě modrou, ale je posunuta o 2 jednotky doleva. Prediktor s Defaultním adresováním a 128 záznamy má zhruba stejnou přesnost jako prediktor s adresováním Shift 2 a pouhými 32 záznamy. Všimněte si, že naše škálování se nyní spravilo - na začátku není žádná hnusná rovná čára.
Fialový Shift 3 už nepředvádí takový posun. Do N=7 drží nad Shift 2 jemnou výhodu, ale tu u velkých prediktorů ztrácí a Shift 2 končí jako vítěz.
Světle modrý Shift 4 má o poznání horší škálování. Při N větším než 9 dokonce prohrává na plné čáře s Defaultním adresováním.
Růžový Shift 5 plní očekávání a předvádí ještě horší škálování - proto jsem ho ani nedotestoval.
Po tomto experimentu lze s určitostí říct, že spodní 2 bity adresy PC se chovají zvláštně (může to působit, jako by se ani vůbec neměnily a zůstávaly pořád stejné, ale díval jsem se a někdy se mění, i když málo často) měli bychom si na ně tedy v budoucnu dávat pozor.
Toto nelze obecně použít u všech procesorů. Domnívám se, že narážíme na nějakou specialitku v architektuře simulovaného procesoru - bohužel netuším na jaké ISA simulovaný procesor běží (možná to ani není nějaká standardní ISA a je to něco speciálně vyvinutého pro CBP), takže těžko říct proč pozorujeme toto chování.
Pro nás je ale důležitý princip - změnou adresování můžeme dosáhnout velmi zajímavých výsledků, což si v budoucnu potvrdíme i na Gshare prediktoru.
Příště se podíváme na Two Level Adaptive predictor.





